

One must imagine the sequencers decentralized — Albert Camus (maybe)
Our experience on rollups is controlled by a shadowy few. The power to verify, order, batch, and subsequently post user transactions to the L1, lies in the hands of faceless entities with unknown motives. Welcome to the dark reality of the current rollups landscape. I’m exaggerating here, but there is a real case to be made against centralized sequencers.
Let us explore the depths of (de)centralized sequencers, and the cape-wearing devs who are building solutions for it. Keep in mind I’m pretty retarded, I will be linking my sources throughout the article.
I’d like to thank Noah Pravecek, founder of NodeKit, for his contribution and feedback on this article. NodeKit is a decentralized shared sequencer built into a custom L1 blockchain which allows rollups to decentralize their sequencer and increase cross-rollup interoperability. Learn more about what NodeKit is buillding on nodekit.gitbook.io/nodekit-documentation.
A quick intro to sequencers — what are they?
Sequencers are a critical piece of infrastructure for layer 2 rollups, yet they are currently being run by centralized entities. Which comes with a set of risks.
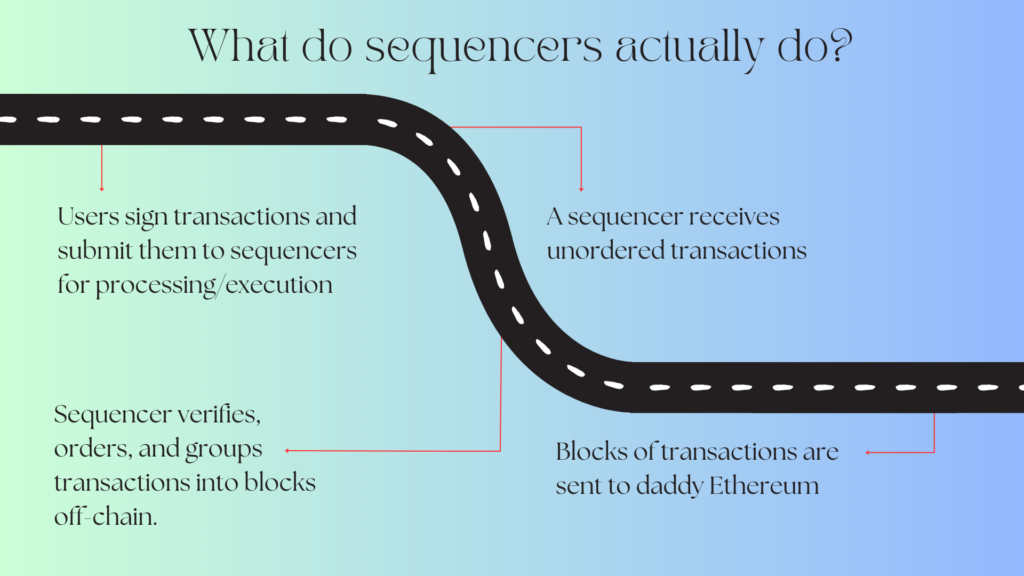
Layer 2 networks (L2s) serve as an execution layer for cheaper, and faster transactions. The data relating to transactions on layer 2’s are sent to the main chain; daddy Ethereum.
Sequencers carry the task of verifying and ordering transactions on the rollup network. All transactions are batched together and sent to the L1. What’s in it for the sequencers? They earn a small portion of the fees collected from users. Especially with the explosive popularity and adoption of L2s, being the main sequencer becomes highly attractive in terms of revenue.
Do we actually need sequencers?
You might be surprised to hear that sequencers are not actually an indispensable part of rollups. It’s a choice to implement them. However, not implementing/utilizing them, means you have to use Ethereum for sequencing transactions. So it’s cheaper and more convenient for rollups to implement a centralized sequencer. It’s also faster, and therefore more user-friendly. Rollups are fun to use solely because they run their own sequencers.
Rollups running their own sequencers makes using the network cheaper, and faster. In the word of the philosopher Borat: WAAAWAAWEEWAAAA ITS A VERY NICE.
The downsides of centralized and decentralized sequencers
As mentioned above, centralized features are a feature, not a bug. They are implemented by choice, to enhance the experience of the user. And judging by the explosive adoption of L2s, it’s a wise choice. However, there is increasing criticism of the centralized model. Let’s explore some of the critiques.
The downside of centralized sequencers:
Censorship
As mentioned earlier, sequencers control the order of transactions. And even hold the power to censor transactions from a specific user. For example, when there’s political pressure to single out certain users. However, it’s worth mentioning that sequencers can’t completely prevent you from using the rollup.
You should always be able to force inclusion of your L2 transactions directly onto the L1 contract, through what we call an escape hatch mechanism. This means you can send transactions directly to the L1. To do so, you have to be willing to pay the higher gas fees needed for this transaction.
A sequencer can stop processing your transactions, but it can’t stop you from forcing the inclusion of your transaction through the escape hatch. The best it can do is slow down your transaction and make you pay extra gas. But it can never completely prevent you from doing transactions.

MEV extraction
Sequencers have off-chain access to all transactions from all users off-chain, and they are the first ones to have it. This leads to criticism/concerns from rollup users and decentralization maxi’s, because sequencers can extract the max MEV potential. Without other network participants having the same visibility.
“Maximal extractable value (MEV) refers to the maximum value that can be extracted from block production in excess of the standard block reward and gas fees by including, excluding, and changing the order of transactions in a block.”
The fact that sequencers can act without transparency, means that there is no real trustlessness, like blockchain tech is meant to have. The true level of decentralization can be questioned as well.
Single point of failure (liveness)
Let’s say you don’t care about decentralization (you might be even dumber than I am). And you also don’t care about the MEV extraction. There is still a real downside to centralized sequencers, as they form a single point of failure.
Liveness is what smarter people than me call it. If a sequencer goes down/offline, it impacts the whole network. And yeah, as we discussed before, users can utilize the escape hatch mechanisms. But that will probably not work for most users if the volume gets very high. It’s also not efficient at all.
And all things considered, aren’t single points of failure the antithesis of blockchain technology?
Interoperability
Yaoqi Jia – founder of AltLayer Network – describes poor interoperability as a downside of centralized sequencers:
“With each rollup running its own siloed sequencer, cross-rollup composability and bridging requires complex custom integrations. Valuable features like cross-chain atomic transactions are difficult to implement across decentralized domains.”
The downside of centralized sequencers:
In an article written by Kyle Liu (Investment Manager at Bing Ventures), he describes many benefits of decentralized sequencers. Such as increased system reliability, transparent/fair transaction ordering, and many other benefits.
He does mention that the current decentralized sequencer solutions are “crude”, whatever that means. The road for improvement moves in the direction of:
- Designing more effective ordering algorithms
- Implementing more robust validation mechanisms
- Creating smarter designs
There are various approaches to both decentralized and shared sequencing. As Kyle rightfully mentions, each comes with certain drawbacks. Shared sequencers, for example, are still limited by the L1’s data and transaction ordering throughput.
Bootstrapping new sequencer sets through token incentive mechanisms will come with increased latency and they are challenging to implement for lesser-known rollups.
Sharing the burden — the case for decentralized/shared sequencers
Blockchain technology is all about decentralization. It’s how Bitcoin got so big. A global, trustless network where you can freely transact and store value as you wish — without anyone coming in between. How cool is that?
It’s been 14 years since the creation of Bitcoin. Blockchain as an industry has grown a lot, and increasingly more applications/networks are being built. Usually, decentralization is at the very core of it. Providing access. Lowering barriers. Empowering the little guy. Making sure things are fair and transparent.

With the explosive growth in L2 adoption, should we not strive to decentralize the very thing that holds the power to verify, order, and execute transactions on these networks? Sounds like a worthy cause to me (keep in mind that I’m pretty retarded).
Lucky for us, there are devs with big brains working on solving this problem. As you now know, it’s not that easy. Why? Because each approach to solving this problem comes with a downside. The parent companies behind most of the top rollup networks are also incentivized to keep running the sequencers themselves for the revenue they generate.
Shared vs. decentralized sequencers
When it comes to making rollup more decentralized, there are generally two paths you can take: shared sequencing or direct decentralized sequencing.

Shared sequencing refers to a network of sequencers who perform their sequencing magic for a multitude of rollups. The shared sequencer layer sorts out transactions and creates one mega block which individual rollups derive their blocks from. Sequencing-as-a-service, if you will.
A bunch of nodes that work together and use some fancy protocol to agree on stuff (consensus). Each rollup doesn’t have to run and maintain its own sequencer. They can just utilize the shared sequencing layer. The shared sequencer network can service any number of rollups. The best part? The utilization of shared sequencing by rollups also favors interoperability and composability between them.
The other school of thought comes in the form of decentralized sequencing, as opposed to shared sequencing. Instead of a network of nodes providing sequencing services to many rollups (shared sequencing), with decentralized sequencing, each rollup has an army of sequencer soldiers. Loyal to just one rollup. And like any good soldier; they follow orders.
Using your own army means you can train and brainwash them however you see fit. So the benefit of this approach is that it allows rollups to design the mechanism to perfectly cater to their needs. It’s also easier for network participants (sequencer nodes, execution nodes) to work together if they run things in their own little bubbles.
Both camps make sense. It all boils down to your specific needs
Fancy rollups with cool features will likely favor having direct decentralized sequencers. But lightweight rollups might be satisfied with integrating a shared sequencing layer to save them the hassle of setting up their own sequencing node army.
The other advantage of shared sequencing is atomic cross-rollup interoperability which could provide better liquidity across rollups. Rollups can use a neutral shared sequencer instead of relying on their own decentralized sequencer set which can be harder to bootstrap and be isolated from other rollups.
In the end. there are different tradeoffs for both approaches so there will be a clear divide in the future of rollups who chose to go down one path or the other.



